Once you have spawned your Garage cluster, you might be interested in finding ways to share efficiently your content with the rest of the world, such as by joining federated platforms. In this blog post, we experiment with interconnecting the InterPlanetary File System (IPFS) daemon with Garage. We discuss the different bottlenecks and limitations of the software stack in its current state.
Some context
People often struggle to see the difference between IPFS and Garage, so let's start by making clear that these projects are complementary and not interchangeable.
Personally, I see IPFS as the intersection between BitTorrent and a file system. BitTorrent remains to this day one of the most efficient ways to deliver a copy of a file or a folder to a very large number of destinations. It however lacks some form of interactivity: once a torrent file has been generated, you can't simply add or remove files from it. By presenting itself more like a file system, IPFS is able to handle this use case out of the box.
However, you would probably not rely on BitTorrent to durably store the encrypted holiday pictures you shared with your friends, as content on BitTorrent tends to vanish when no one in the network has a copy of it anymore. The same applies to IPFS. Even if at some time everyone has a copy of the pictures on their hard disk, people might delete these copies after a while without you knowing it. You also can't easily collaborate on storing this common treasure. For example, there is no automatic way to say that Alice and Bob are in charge of storing the first half of the archive while Charlie and Eve are in charge of the second half.
➡️ IPFS is designed to deliver content.
Note: the IPFS project has another project named IPFS Cluster that allows servers to collaborate on hosting IPFS content. Resilio and Syncthing both feature protocols inspired by BitTorrent to synchronize a tree of your file system between multiple computers. Reviewing these solutions is out of the scope of this article, feel free to try them by yourself!
Garage, on the other hand, is designed to automatically spread your content over all your available nodes, in a manner that makes the best possible use of your storage space. At the same time, it ensures that your content is always replicated exactly 3 times across the cluster (or less if you change a configuration parameter), on different geographical zones when possible.
However, this means that when content is requested from a Garage cluster, there are only 3 nodes capable of returning it to the user. As a consequence, when content becomes popular, this subset of nodes might become a bottleneck. Moreover, all resources (keys, files, buckets) are tightly coupled to the Garage cluster on which they exist; servers from different clusters can't collaborate to serve together the same data (without additional software).
➡️ Garage is designed to durably store content.
In this blog post, we will explore whether we can combine efficient delivery and strong durability by connecting an IPFS node to a Garage cluster.
Try #1: Vanilla IPFS over Garage
IPFS is available as a pre-compiled binary, but to connect it with Garage, we need a plugin named ipfs/go-ds-s3. The Peergos project has a fork because it seems that the plugin is known for hitting Amazon's rate limits (#105, #205). This is the one we will try in the following.
The easiest solution to use this plugin in IPFS is to bundle it in the main IPFS daemon, and recompile IPFS from sources. Following the instructions on the README file allowed me to spawn an IPFS daemon configured with S3 as the block store.
I had a small issue when adding the plugin to the plugin/loader/preload_list file: the given command lacks a newline.
I had to edit the file manually after running it, the issue was directly visible and easy to fix.
After that, I just ran the daemon and accessed the web interface to upload a photo of my dog:

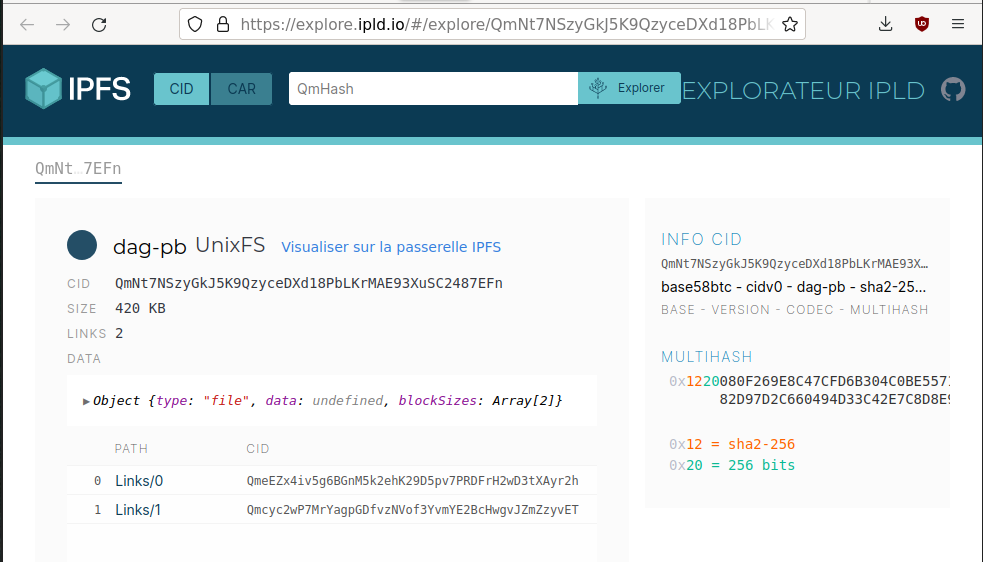
A content identifier (CID) was assigned to this picture:
QmNt7NSzyGkJ5K9QzyceDXd18PbLKrMAE93XuSC2487EFn
The photo is now accessible on the whole network. For example, you can inspect it from the official gateway:
At the same time, I was monitoring Garage (through the OpenTelemetry stack we implemented earlier this year). Just after launching the daemon - and before doing anything - I was met by this surprisingly active Grafana plot:
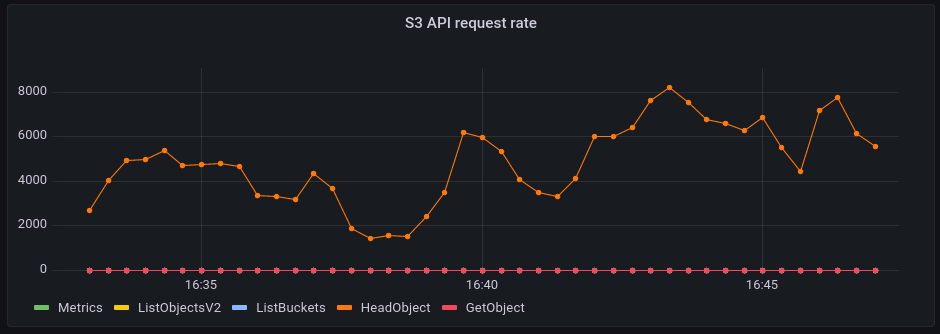
It shows that on average, we handle around 250 requests per second. Most of these requests are in fact the IPFS daemon checking if a block exists in Gargage. These requests are triggered by IPFS's DHT service: since my node is reachable over the Internet, it acts as a public DHT server and has to answer global block requests over the whole network. Each time it receives a request for a block, it sends a request to its storage back-end (in our case, to Garage) to see if a copy exists locally.
We will try to tweak the IPFS configuration later - we know that we can deactivate the DHT server. For now, we will continue with the default parameters.
When I started interacting with the IPFS node by sending a file or browsing the default proposed catalogs (i.e. the full XKCD archive), I quickly hit limits with our monitoring stack which, in its default configuration, is not able to ingest the large amount of tracing data produced by the high number of S3 requests originating from the IPFS daemon. We have the following error in Garage's logs:
OpenTelemetry trace error occurred. cannot send span to the batch span processor because the channel is full
At this point, I didn't feel that it would be very interesting to fix this issue to see what was exactly the number of requests done on the cluster. In my opinion, such a simple task of sharing a picture should not require so many requests to the storage server anyway. As a comparison, this whole webpage, with its pictures, triggers around 10 requests on Garage when loaded, not thousands.
I think we can conclude that this first try was a failure. The S3 storage plugin for IPFS does too many requests and would need some important work to be optimized. However, we are aware that the people behind Peergos are known to run their software based on IPFS in production with an S3 backend, so we should not give up too fast.
Try #2: Peergos over Garage
Peergos is designed as an end-to-end encrypted and federated alternative to Nextcloud. Internally, it is built on IPFS and is known to have a deep integration with the S3 API. One important point of this integration is that your browser is able to bypass both the Peergos daemon and the IPFS daemon to write and read IPFS blocks directly from the S3 API server.
I don't know exactly if Peergos is still considered alpha quality, or if a beta version was released, but keep in mind that it might be more experimental than you'd like!
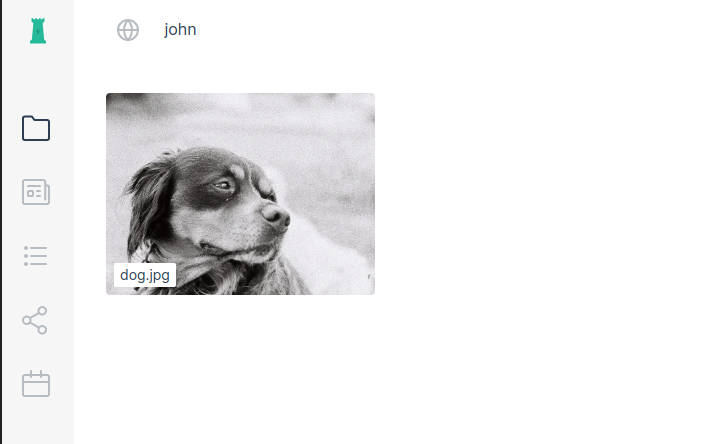
Starting Peergos on top of Garage required some small patches on both sides, but in the end, I was able to get it working. I was able to upload my file, see it in the interface, create a link to share it, rename it, move it to a folder, and so on:
At the same time, the fans of my computer started to become a bit loud! A quick look at Grafana showed again a very active Garage:
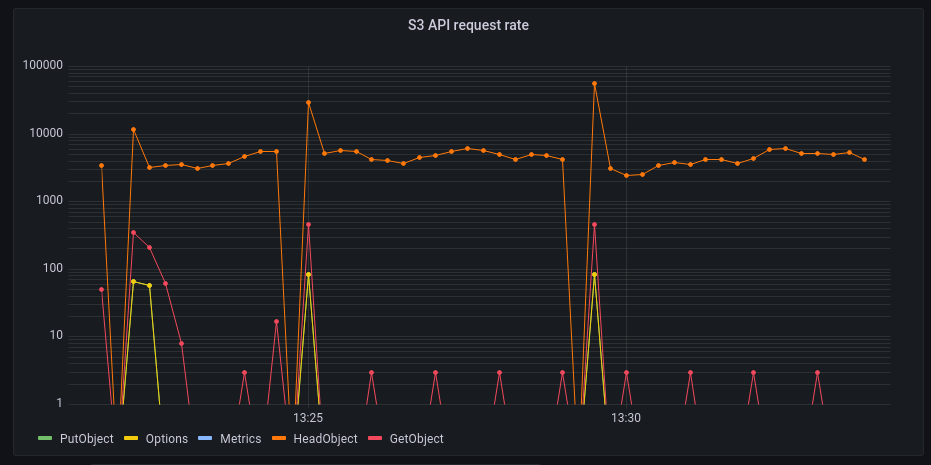
Again, the workload is dominated by S3 HeadObject requests.
After taking a look at ~/.peergos/.ipfs/config, it seems that the IPFS configuration used by the Peergos project is quite standard,
which means that, as before, we are acting as a DHT server and having to answer to thousands of block requests every second.
We also have some traffic on the GetObject and OPTIONS endpoints (with peaks up to ~45 req/sec).
This traffic is all generated by Peergos.
The OPTIONS HTTP verb is here because we use the direct access feature of Peergos,
meaning that our browser is talking directly to Garage and has to use CORS to validate requests for security.
Internally, IPFS splits files into blocks of less than 256 kB. My picture is thus split into 2 blocks, requiring 2 requests over Garage to fetch it.
But even knowing that IPFS splits files into small blocks, I can't explain why we have so many GetObject requests.
Try #3: Optimizing IPFS
We have seen in our 2 previous tries that the main source of load was the federation and in particular the DHT server. In this section, we'd like to artificially remove this problem from the equation by preventing our IPFS node from federating and see what pressure is put by Peergos alone on our local cluster.
To isolate IPFS, I have set its routing type to none, I have cleared its bootstrap node list,
and I configured the swarm socket to listen only on localhost.
Finally, I restarted Peergos and was able to observe this more peaceful graph:
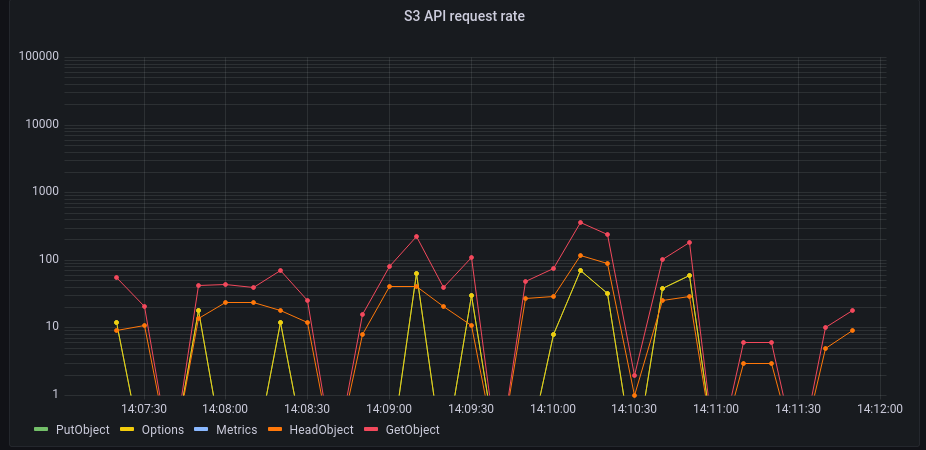
Now, for a given endpoint, we have peaks of around 10 req/sec which is way more reasonable. Furthermore, we are no longer hammering our back-end with requests on objects that are not there.
After discussing with the developers, it is possible to go even further by running Peergos without IPFS: this is what they do for some of their tests. If at the same time we increased the size of data blocks, we might have a non-federated but quite efficient end-to-end encrypted "cloud storage" that works well over Garage, with our clients directly hitting the S3 API!
For setups where federation is a hard requirement,
the next step would be to gradually allow our node to connect to the IPFS network
while ensuring that the traffic to the Garage cluster remains low.
For example, configuring our IPFS node as a dhtclient instead of a dhtserver would exempt it from answering public DHT requests.
Keeping an in-memory index (as a hash map and/or a Bloom filter) of the blocks stored on the current node
could also drastically reduce the number of requests.
It could also be interesting to explore ways to run in one process a full IPFS node with a DHT
server on the regular file system, and reserve a second process configured with the S3 back-end to handle only our Peergos data.
However, even with these optimizations, the best we can expect is the traffic we have on the previous plot. From a theoretical perspective, it is still higher than the optimal number of requests. On S3, storing a file, downloading a file, and listing available files are all actions that can be done in a single request. Even if all requests don't have the same cost on the cluster, processing a request has a non-negligible fixed cost.
Are S3 and IPFS incompatible?
Tweaking IPFS in order to try and make it work on an S3 backend is all and good, but in some sense, the assumptions made by IPFS are fundamentally incompatible with using S3 as block storage.
First, data on IPFS is split in relatively small chunks: all IPFS blocks must be less than 1 MB, with most being 256 KB or less. This means that large files or complex directory hierarchies will need thousands of blocks to be stored, each of which is mapped to a single object in the S3 storage back-end. On the other side, S3 implementations such as Garage are made to handle very large objects efficiently, and they also provide their own primitives for rapidly listing all the objects present in a bucket or a directory. There is thus a huge loss in performance when data is stored in IPFS's block format because this format does not take advantage of the optimizations provided by S3 back-ends in their standard usage scenarios. Instead, it requires storing and retrieving thousands of small S3 objects even for very simple operations such as retrieving a file or listing a directory, incurring a fixed overhead each time.
This problem is compounded by the design of the IPFS data exchange protocol, in which nodes may request any data blocks to any other node in the network in its quest to answer a user's request (like retrieving a file, etc.). When a node is missing a file or a directory it wants to read, it has to do as many requests to other nodes as there are IPFS blocks in the object to be read. On the receiving end, this means that any fully-fledged IPFS node has to answer large numbers of requests for blocks required by users everywhere on the network, which is what we observed in our experiment above. We were however surprised to observe that many requests coming from the IPFS network were for blocks which our node didn't have a copy of: this means that somewhere in the IPFS protocol, an overly optimistic assumption is made on where data could be found in the network, and this ends up translating into many requests between nodes that return negative results. When IPFS blocks are stored on a local filesystem, answering these requests fast might be possible. However, when using an S3 server as a storage back-end, this becomes prohibitively costly.
If one wanted to design a distributed storage system for IPFS data blocks, they would probably need to start at a lower level. Garage itself makes use of a block storage mechanism that allows small-sized blocks to be stored on a cluster and accessed rapidly by nodes that need to access them. However passing through the entire abstraction that provides an S3 API is wasteful and redundant, as this API is designed to provide advanced functionality such as mutating objects, associating metadata with objects, listing objects, etc. Plugging the IPFS daemon directly into a lower-level distributed block storage like Garage's might yield way better results by bypassing all of this complexity.
Conclusion
Running IPFS over an S3 storage backend does not quite work out of the box in terms of performance. Having identified that the main problem is linked to the DHT service, we proposed some improvements (disabling the DHT server, keeping an in-memory index of the blocks, and using the S3 back-end only for user data).
From an IPFS design perspective, it seems however that the numerous small blocks handled by the protocol do not map trivially to efficient use of the S3 API, and thus could be a limiting factor to any optimization work.
As part of my testing journey, I also stumbled upon some posts about performance issues on IPFS (eg. #6283) that are not linked with the S3 connector. I might be negatively influenced by my failure to connect IPFS with S3, but at this point, I'm tempted to think that IPFS is intrinsically resource-intensive from a block activity perspective.
On our side at Deuxfleurs, we will continue our investigations towards more minimalistic software. This choice makes sense for us as we want to reduce the ecological impact of our services by deploying fewer servers, that use less energy, and are renewed less frequently.
After discussing with Peergos maintainers, we identified that it is possible to run Peergos without IPFS. With some optimizations on the block size, we envision great synergies between Garage and Peergos that could lead to an efficient and lightweight end-to-end encrypted "cloud storage" platform. If you happen to be working on this, please inform us!
We are also aware of the existence of many other software projects for file sharing such as Nextcloud, Owncloud, Owncloud Infinite Scale, Seafile, Filestash, Pydio, SOLID, Remote Storage, etc. Many of these could be connected to an S3 back-end such as Garage. We might even try some of them in future blog posts, so stay tuned!